购买kindle之后,自然欣喜万分,不来自于工具本身,而来自于发现自己能够静下心来阅读长篇和复杂的文字了,可喜可贺。更重要的是,kindle减轻了我眼睛的莫大的压力。但马上就出现几个问题:
- 不是所有的电子书都有kindle,最常见的是扫描PDF
- 大量的论文无法阅读,这和上面的问题一致
- 网络上很多精彩的博客,新闻,都是没法阅读的
可能有人说,用手机看不就得了?用手机看花边娱乐新闻当然很好,可是当看数学推导时,推送栏上面妹子发来的消息,会直接把你的思路全部打乱。没用过kindle的人,是有些难以体会那种接近于纸张的质感的。OK,既然是程序员,我们就尝试解决这些问题。
有关kindlegen和HTML
kindlegen是亚马逊官方出品的一个电子书生成工具。但它明显就没打算让普通用户使用,命令行界面,几乎没有任何像样的文档。只是在实例样例里给了几个生成电子书的文件。我就因为没有文档兜了大弯,翻遍国外各大网站,才慢慢摸清kindlegen的使用细节。
可以这么理解,KG是将一组HTML和相关文件,打包成mobi文件的工具。
最简单的例子,随意编写一个HTML文件,送给KG,会生成对应的mobi。基本有title,h1,h2,正文,kindle渲染就差不多了。如果需要修改样式,可以提供CSS文件。
但是,这样的做法,没有图片,没有超链接,无法提供目录,如果输入单一的大型HTML文件,kindle的渲染性能就不足了。
因此,需要生成层级化,多文件形式的html文件夹,然而kg并不能直接识别html文件夹,还是需要一些元数据描述。
编写元数据文件
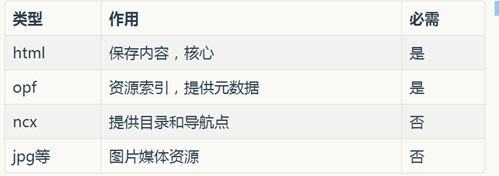
要想解决这个问题,就需要编写两个文件,opf和ncx, 他们可以理解为KG的makefile, KG通过这两个文件索引HTML,目录和其他多媒体资源。介绍如下:
[ ][1]
][1]
值得注意的是,所有的文件都应该保存在本地,尤其是jpg, html中的图片超链接,需要重定向到本地的jpg文件,如果依然在服务器上,据我所知,kg是不负责渲染下载的。
资源聚合文件: opf和ncx
由于opf文件非常重要,我们下面就讲解opf的格式:
<metadata xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:opf="http://www.idpf.org/2007/opf">
<dc:title>电子书标题</dc:title>
<dc:language>en-us</dc:language>
</metadata>
<manifest>
<!-- table of contents [mandatory] -->
<item id="tochtml" media-type="application/xhtml+xml" href="toc.html"/>
<item id="item0" media-type="application/xhtml+xml" href="Artical-1277621753.html"/>
...
<!--下面是图片-->
<item id="0.368541311142" media-type="image/jpg" href="Images/-1720404282.jpg"/>
</manifest>
<spine toc="desertfire">
<!-- 下面描述了KG生成电子书后文本的顺序 -->
<itemref idref="toc"/>
<itemref idref="tochtml"/>
<itemref idref="item31"/>
</spine>
<guide>
<reference type="toc" title="Table of Contents" href="toc.html"></reference>
<reference type="text" title="Welcome" href="toc.html"></reference>
</guide>
</package>
```" data-snippet-id="ext.b091e89925c72be7b07f9caa16092df4" data-snippet-saved="false" data-codota-status="done"><package xmlns="http://www.idpf.org/2007/opf" version="2.0" unique-identifier="BookId">
<metadata xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:opf="http://www.idpf.org/2007/opf">
<dc:title>电子书标题</dc:title>
<dc:language>en-us</dc:language>
</metadata>
<manifest>
<!-- table of contents [mandatory] -->
<item id="tochtml" media-type="application/xhtml+xml" href="toc.html"/>
<item id="item0" media-type="application/xhtml+xml" href="Artical-1277621753.html"/>
...
<!--下面是图片-->
<item id="0.368541311142" media-type="image/jpg" href="Images/-1720404282.jpg"/>
</manifest>
<spine toc="desertfire">
<!-- 下面描述了KG生成电子书后文本的顺序 -->
<itemref idref="toc"/>
<itemref idref="tochtml"/>
<itemref idref="item31"/>
</spine>
<guide>
<reference type="toc" title="Table of Contents" href="toc.html"></reference>
<reference type="text" title="Welcome" href="toc.html"></reference>
</guide>
</package>
<div class="cnblogs_code_toolbar">
<span class="cnblogs_code_copy"><a title="复制代码"></a></span>
</div>
</div>
[][2]
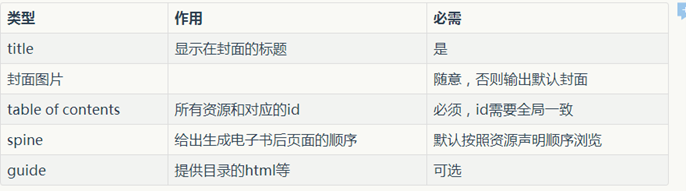
需要注意的有以下几点:
* 所有资源都需要一个id,命名任意,但不能重复
* media-type描述了资源的类型,记住两类基本就够用了,”application/xhtml+xml”代表HTML文件,”image/jpg”或 “image/png”代表图片。
* 其他都可以省略,只是会影响电子书完整性。
由于这两个文件内部其实都是html,所以修改编辑都很容易。
**最终,KG的命令行目标,不是目录HTML,而是OPF文件!**将所有的文件放入一个文件夹后,启动KG命令行,最后KG会在该目录下生成你心仪已久的mobi!
## 编辑HTML和OPF文件
知道其原理后,主要的任务是填充HTML和OPF文件,几页内容还好,如果内容繁多,不论是手工**( ⊙ o ⊙ )**,还是编程字符串拼接,都会变得异常低效。
此时,就需要**模板引擎**出手了,python推荐使用Jinja2, 资料众多,功能强大,性能尚可。生成opf的模板文件,基本就长下面这个样子:
<div class="cnblogs_code">
<div class="cnblogs_code_toolbar">
<span class="cnblogs_code_copy"><a title="复制代码"></a></span>
</div>
<div class="top-box hide">
<div class="alert-info">
</div>
</div>
</manifest>
<spine toc="{{ title }}">
<!– the spine defines the linear reading order of the book –>
<itemref idref=“toc”/>
<itemref idref=“tochtml”/>
{% for item in navigation %}
<itemref idref="{{ item.id }}"/>
{% endfor %}
</spine>
<guide>
<reference type=“toc” title=“Table of Contents” href=“toc.html”></reference>
<reference type=“text” title=“Welcome” href=“toc.html”></reference>
</guide>
</package>
<div class="cnblogs_code_toolbar">
<span class="cnblogs_code_copy"><a title="复制代码"></a></span>
</div>
</div>
我在此处就不费事讲解jinja2的语法了。这样,就能解决阅读网页新闻和HTML资源的问题了。
## 生成扫描版MOBI
下一个问题,是如何阅读扫描版的PDF,如电子书和论文。有以下几类初始想法:
[][3]
权衡之后,我们选用第二种方案。PDF分为两类,一种是一页一栏,如电子书,另一种是一页两栏,如论文。
那么,为了保证质量,有以下的步骤:
### 将PDF转换为图片
如果使用python,则有一些类库可以使用,如imagemagick和一系列相关类库。
但这些类库安装比较麻烦,因此笔者使用了软件生成,此处强烈推荐一款软件:
**AP PDF to IMAGE** 国产软件?的骄傲!不需要其他任何类库,体积小,性能稳定,生成图片尺寸可调,可批量处理,非常清晰!
百度可搜索各类绿色版下载,我都想给作者支付宝捐钱了。
### 图片处理
如果你是PS大神,当然可以使用宏和批量命令完成这些,此处我们用的还是python,使用著名的PIL类库,下面贴出代码:
<div class="cnblogs_code">
<div class="cnblogs_code_toolbar">
<span class="cnblogs_code_copy"><a title="复制代码"></a></span>
</div>
<div class="top-box hide">
<div class="alert-info">
</div>
</div>
coding=utf-8
import os
import Image as img import jinja2 as jj
import extends import libs.kindlestrip as kp
要PDF转JPG时,如果用python的方案,则需要安装一堆库
用现成的工具,则难以与Python集成,而且速度很慢,目前还是采用现成的工具吧
当生成论文时,第一页的上半部分,单独抽出,剩下的分为四页导出。设置如下
horizon = 2 vertic = 2 firstpage = True
生成普通横版PDF时,则为如下设置:
horizon = 1
vertic = 2
firstpage=False
topblood = 0.05; sideblood = 0.06; booktitle = u"Paper"; author = “zhaoyiming” outputfolder = “pdf2mobi/”; imgTypes = [’.png’, ‘.jpg’, ‘.bmp’] kindlegen = r"Tools/kindlegen.exe" # kindlegen position shouldsplit = True; imagefolders = outputfolder + ‘raw’; splitfolder = outputfolder + ‘split’
docs = []; pageindex = 0;
if shouldsplit == True: for root, dirs, files in os.walk(imagefolders): index = 0; for currentFile in files: crtFile = root + ‘\’ + currentFile format = crtFile[crtFile.rindex(’.’):].lower();
if format not in imgTypes:
continue;
crtIm = img.open(crtFile)
crtW, crtH = crtIm.size
hStep = crtW * (1 - 2 * sideblood) // horizon
vStep = crtH * (1 - 2 * topblood) // vertic
hstart = crtW * sideblood
vstart = crtH * topblood;
if (firstpage == True and pageindex == 0):
crtOutFileName = 'pdf2mobi/split/' + str(index) + format,
box = (hstart, vstart, crtW, crtH // 3)
box = list((int(x) for x in box));
cropped = crtIm.crop(box)
cropped.save(crtOutFileName[0])
myimg = {};
myimg["href"] = "split/" + str(index) + format;
myimg["id"] = index;
myimg["format"] = format;
myimg["width"] = box[2] - box[0];
myimg["height"] = box[3] - box[1];
docs.append(myimg)
index += 1;
for j in range(horizon):
for i in range(vertic):
crtOutFileName = 'pdf2mobi/split/' + str(index) + format,
box = (hstart + j * hStep, vstart + i * vStep, hstart + (j + 1) * hStep, vstart + (i + 1) * vStep)
box = (int(x) for x in box);
cropped = crtIm.crop(box)
cropped.save(crtOutFileName[0])
myimg = {};
myimg["href"] = "split/" + str(index) + format;
myimg["id"] = index;
myimg["format"] = format;
myimg["width"] = hStep;
myimg["height"] = vStep;
docs.append(myimg)
index += 1;
pageindex += 1;
else: for root, dirs, files in os.walk(imagefolders): index = 0; for currentFile in files: crtFile = root + ‘\’ + currentFile format = crtFile[crtFile.rindex(’.’):].lower(); if format not in imgTypes: continue; myimg = {}; myimg[“href”] = “split/” + str(index) + format; myimg[“id”] = index; myimg[“format”] = format; myimg[“width”] = “1347”; myimg[“height”] = “1023”; docs.append(myimg) index += 1; images = []; env = jj.Environment(loader=jj.FileSystemLoader([r"templates/"])) articaltemplate = env.get_template(‘jpgs.html’)
opftemplate = env.get_template(‘opf.html’) ncxtemplate = env.get_template(’ncx.html’)
extends.SaveFile(outputfolder + “toc.html”, articaltemplate.render(navigation=docs, title=booktitle, author=author)); extends.SaveFile(outputfolder + booktitle + “.opf”, opftemplate.render(navigation=docs, title=booktitle, author=author, media=images)); extends.SaveFile(outputfolder + “toc.ncx”, ncxtemplate.render(navigation=docs, title=booktitle, author=author));
currentPath = os.getcwd() + “\” + outputfolder.replace("/", “\”) + booktitle + “.opf”; mobipath = outputfolder.replace("/", “\”) + booktitle + “.mobi”; kindlepath = os.getcwd() + “\” + kindlegen.replace("/", “\”); cmd = kindlepath + " " + currentPath; cmd = cmd.encode(); print cmd; os.system(cmd); kp.Convert(mobipath, mobipath)
<div class="cnblogs_code_toolbar">
<span class="cnblogs_code_copy"><a title="复制代码"></a></span>
</div>
</div>
(我觉得我应该把代码上传到github上,恩,一会再说)
这样,就能生成可读的漂亮的PDF转mobi了。
## 最终效果
这些代码花了我一个下午的时间,不过与爬虫配合,生成各位大神的博客,效果真是非常赞!
[][4]
[][5]
[][6]
转自:https://www.cnblogs.com/buptzym/p/5249662.html
[1]: http://images2015.cnblogs.com/blog/287060/201603/287060-20160307103010366-1904378733.png
[2]: http://images2015.cnblogs.com/blog/287060/201603/287060-20160307103011335-1351277383.png
[3]: http://images2015.cnblogs.com/blog/287060/201603/287060-20160307103012491-565994533.png
[4]: http://images2015.cnblogs.com/blog/287060/201603/287060-20160307103014975-1772613163.png
[5]: http://images2015.cnblogs.com/blog/287060/201603/287060-20160307103019960-1840843224.png
[6]: http://images2015.cnblogs.com/blog/287060/201603/287060-20160307103025741-1801716572.png
💬 评论